Short description of the article
Intro
Options of State Management in Angular
Hierarchical component’s interaction
Angular services, variables & Promises
Observable Data Services - Angular services with RxJS
Redux Pattern with RxJS
Conclusion
Intro
Junior developers mostly work with small applications but when they start building large apps they encounter lots of challenges that only the state management may solve.
If you do many simple things which require a lot of data manipulation, as a result, you may face data mutations and the appearance of side-effects. In case, yu don't have much time to solve such problems as fatigue bugs, and poor application performance you’d better learn about state management and how you will benefit from it.
As our team works with Angular we have already come through the same way of large app development and are going to consider all the options of handling a state management in the scope of Angular.
This article provides you with essential comments on how to choose the best option of the state management when building large-scale web apps.
Options of State Management in Angular
There are 2 built-in state functionality options Angular provides us with, and 2 more powerful and efficient options. Let’s consider each of them:
Through hierarchical component’s interaction, typically use of “smart” and “dumb” components via input bindings and custom events.
Through Angular services by using simple variables and Promises.
Through Observable data services.
Through Redux pattern.
Hierarchical component’s interaction
Angular comes with a simple and clear interaction structure: a “stateful” parent component delegates data down into “stateless” children components. Its pro is testing simplicity and transparency: if there are some changes in a parent component, you can easily track down which of the child components are influenced (see Picture 1).
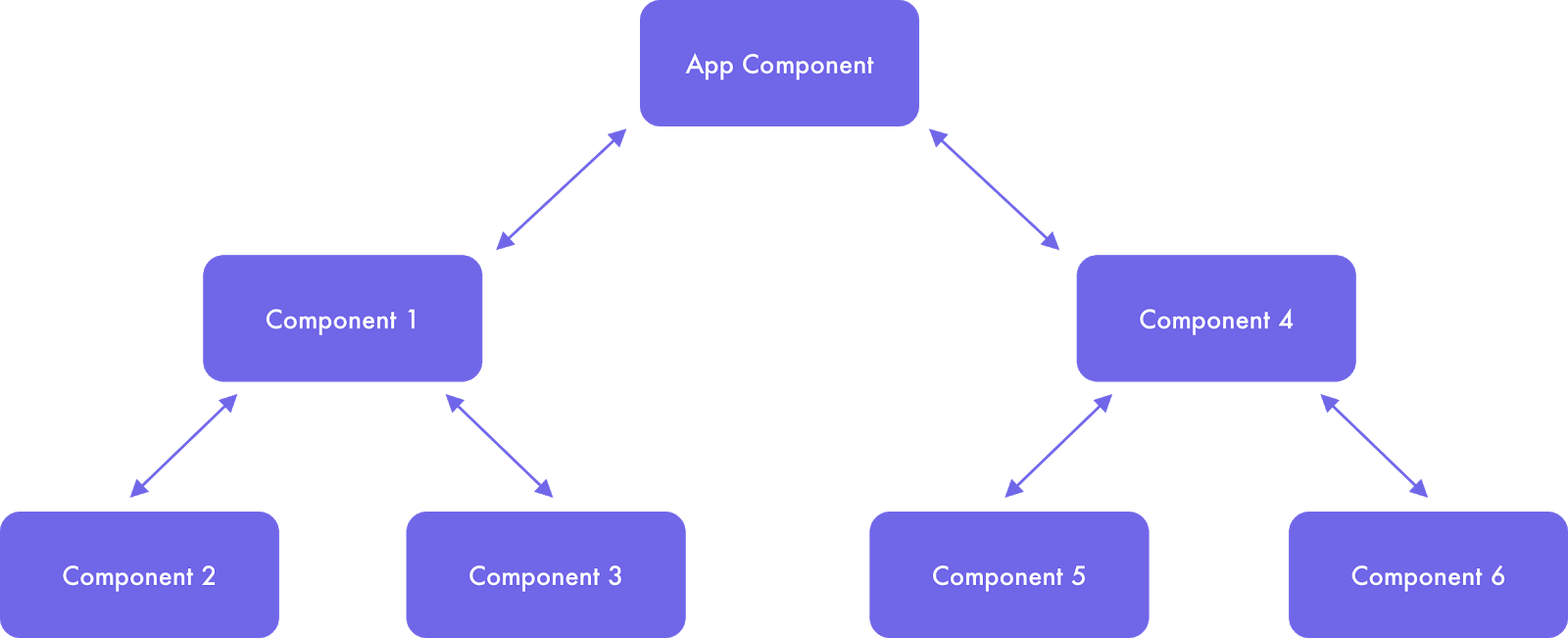
Picture 1
It’s a good solution if your app is simple. As soon as the architecture of this application becomes more complex or if you want to share data between separate modules/components through Angular services, this process becomes confusing (see Picture 2).
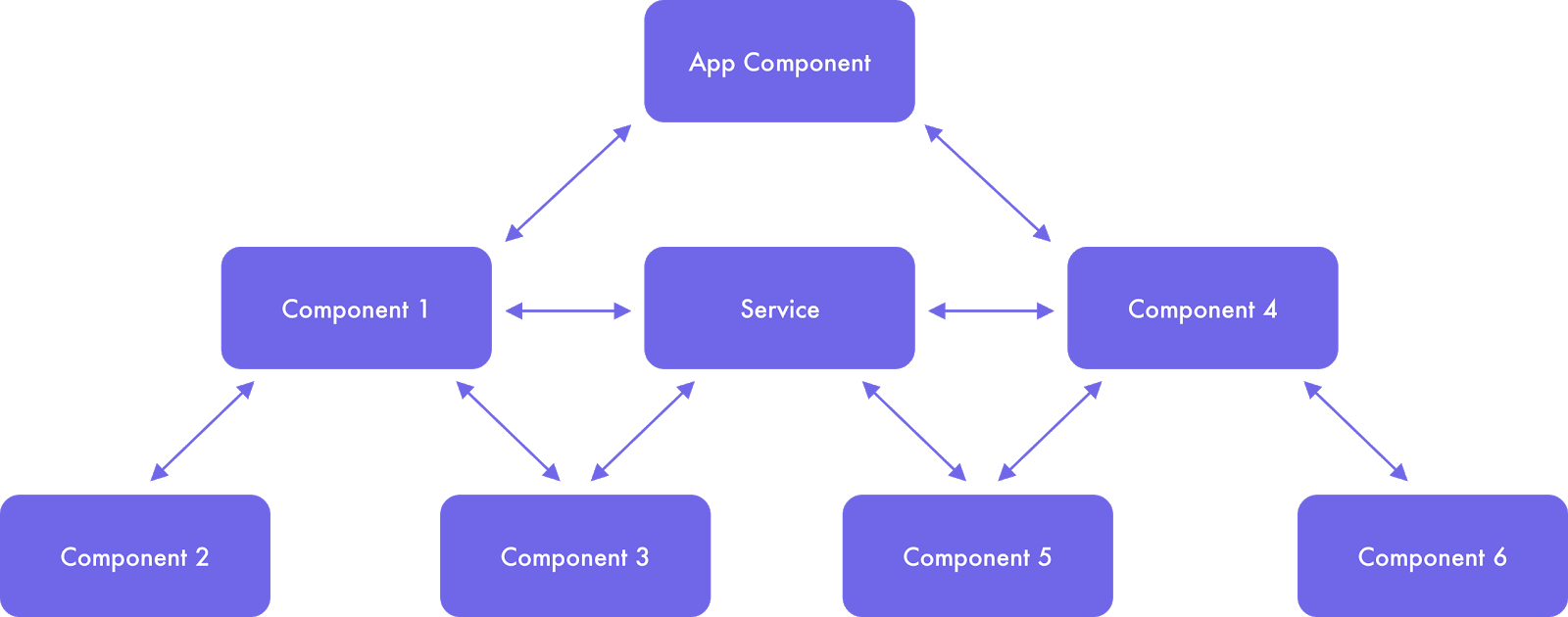
Picture 2
Angular services, variables & Promises
The current approach has some advantages as well as disadvantages. It’s possible to use this approach but only within a very simple application. Let’s explain the reasons of this statement.
When talking about large applications there are some problems in using this approach. First of all, it appears when using simple variables for temporary data saving. It’s impossible simultaneously and over time to monitor data changes in multiple separate components through Angular services properly. Moreover, there’s a huge chance of mutation the same data instance by reference in one of the components, which leads to unpredictable issues and consequences through the entire application.
The second drawback is Promises. As you know Angular offers support of Observables, which facilitates handling multiple values over time, the usage of Promises with its single values looks like a backward step!
The cons of Promises:
-
It’s impossible to run Promise every time you need it because it executes instantly and only once - at the inception;
-
You can get only a single value or an error message from Promise;
-
You can’t cancel the request initiated from a Promise e.g. an HTTP request that does a search on the key-up event would be executed as many times as we press the key;
-
When you are trying to regain a retry capability of a failed call - this can lead to a callback hell.
It follows from the above, that Promises have issues in large-scale apps, besides, we lose a vast functionality when compared with the Observable pattern.
The mentioned above build-in approaches might be applicable for the small applications. Let’s imagine that our app is growing and has a lot of components. That’s why we are going to consider another built-in Angular toolbox - RxJS.
Observable Data Services - Angular services with RxJS
RxJS might be a good solution to the issues concerning Promises and data changing over time. Let’s discuss what are Observables data services. These are data streams which offer higher flexibility when creating an app and managing the state of the app with a help of multiple Angular services (singletons).
The Observable store pattern is a better solution and is more useful for simple apps than a bulky third-party library store. But this approach has its cons, as well. If you are developing an app and trying to carry out the custom state management, you’ll miss the unified and centralized system in this approach.
Here’s a simple app which was written on Angular 5 and RxJS 5.5.11 version. This app has got three main routes:
-
Customers - there is a list of customers with its details.
-
Products - there is a list of products with its details.
-
Invoices - there is a list on invoices and its details.
Additionally, the users can add a new invoice, as well as view, edit and remove a specific invoice.
@Injectable()
export class InvoicesService {
passInvoicesRequest: Subject<any> = new Subject();
invoicesList$: ConnectableObservable<Invoice[]>;
invoicesListCombined$: Observable<Invoice[]>;
invoicesCollection$: ConnectableObservable<Invoice[]>;
addInvoice$: Subject<Invoice> = new Subject();
addInvoiceToCollection$: Observable<any>
deleteInvoice$: Subject<string> = new Subject();
deleteInvoiceOpenModal$: Subject<string> = new Subject();
deleteInvoiceFromCollection$: Observable<Invoice[]>;
deleteInvoiceModal$: ConnectableObservable<Invoice>;
constructor(
private httpClient: HttpClient,
private customersService: CustomersService,
private productsService: ProductsService,
private modalBoxService: ModalBoxService,
) {
// get initial invoices collection
this.invoicesList$ = this.passInvoicesRequest.pipe(
mergeScan(acc => acc ? Observable.of(acc) : this.getInvoicesRequest(), null),
).publishReplay(1);
this.invoicesList$.connect();
// add customer info to initial invoices collection
this.invoicesListCombined$ = combineLatest(
this.invoicesList$,
this.customersService.customersList$.pipe(take(1))
).pipe(
map(([invoices, customers]) => invoices.map(invoice =>
({
...invoice,
customer: customers.find(customer => invoice.customer_id === customer._id),
}))
),
);
// add a new invoice to a collection
this.addInvoiceToCollection$ = this.addInvoice$.pipe(
switchMap(newInvoice => this.invoicesCollection$.pipe(
withLatestFrom(this.customersService.customersList$),
map(([invoices, customers]) =>
[
...invoices,
{
...newInvoice,
customer: customers.find(customer => newInvoice['customer_id'] === customer._id)
},
]
),
take(1),
))
);
// delete an invoice from collection
this.deleteInvoiceFromCollection$ = this.deleteInvoice$.pipe(
switchMap(id => this.invoicesCollection$.pipe(
map(invoices => invoices.filter(invoice => invoice._id !== id)),
take(1),
))
);
// open delete-invoice modal window and send delete request to DB by confirm from user
this.deleteInvoiceModal$ = this.deleteInvoiceOpenModal$.pipe(
mergeMap(id => this.modalBoxService.confirmModal('Are you sure you want to delete an invoice?').pipe(
filter(choice => !!choice),
mapTo(id),
)),
switchMap(id => this.deleteInvoiceRequest(id)),
tap(invoices => this.modalBoxService.confirmModal(`Invoice number ${invoices._id} has been deleted`, false)),
).publishReplay(1);
this.deleteInvoiceModal$.connect();
// main invoices collection to display
this.invoicesCollection$ = Observable.merge(
this.invoicesListCombined$.pipe(take(1)),
this.addInvoiceToCollection$,
this.deleteInvoiceFromCollection$,
).publishReplay(1);
this.invoicesCollection$.connect();
}
getInvoicesRequest() {
return this.httpClient.get<Invoice[]>('invoices');
}
getInvoices() {
this.passInvoicesRequest.next();
return this.invoicesList$;
}
deleteInvoiceRequest(id) {
return this.httpClient.delete<Invoice>(`invoices/${id}`).pipe(
tap(deletedInvoice => this.deleteInvoice$.next(deletedInvoice._id))
);
}
}
We should mention that this approach relies on pure RxJS streams.
The first step is to fetch data from API in invoicesList$ stream, then to pass its value (a collection of invoices) to invoicesListCombined$ stream (it contains customersList$ stream (a collection of customers) declared in customers service). This stream is just transforming every invoice by appending customer info to it.
Then we’re going to carry out functionality within invoices in accordance with the specs and to be able to expand it in the future.
So, the second step is to create the invoicesCollection$ base stream that has an async subscription in a template for displaying a whole invoice list to the user.
As you can see, this stream was expanded with 2 other streams: addInvoiceToCollection$ and deleteInvoiceFromCollection$, which accordingly transform the data of the main invoicesCollection$ stream.
This approach is not going to be simple as you can imagine and we’ll tell you why.
To use it, you should understand the RxJS operators very well;
You have to define which streams are supposed to be “hot”, “cold” or “warm” and whether they are re-used in other services/components or not;
It’s easy to get confused and after that, you’ll have to work a lot on debugging;
The main drawback of this approach is that it’s scalable just within this current service and couldn’t be reusable. The reason is that you will have to repeat and modify the ready code in the other service if you work with other data.
Although the above-mentioned approach is working really fast, we have tried to find out a more efficient solution that could be scalable and reusable for the whole app. We spent some time and found such a solution that unfortunately wasn’t worth that. That solution should follow the DRY principle and make the State implementation reusable entirely through the Angular application that’s why at first, we have created a generic type Class (e.g. class StateManagement).
Secondly, we have added a simple collection$ stream to this Class - it would represent the future data collections. Each time when StateManagement Class is called through the “new” operator - a new instance of this Class would be created with new data inside of collection$ stream.
export class InvoiceService {
state: StateManagement<Invoice>;
constructor() {
this.state = new StateManagement<Invoice>();
// this.state.collection$ would contain collection of invoices
}
}
...
Then, we added to the Class basic CRUD functions of persistent storage because we wanted to be able to transform data in the future. So, when comparing with the previous example all code that was responsible for managing the application State was declared only in one place. That could be called a significant enhancement but two main problems which appeared within this approach should be mentioned here, as well:
Combining different separate States - unfortunately, it’s very easy to get confused with many “CombineLatest” across the whole application. Because of this problem, the code becomes more complex and less readable.
Sequential requests and catching/processing errors As an example, we wanted to get the State of Users and then to get a State for specific Invoices based on a current User Id. As the “StateManagement” Class is unified it becomes a problem to find a proper place for this specific request to be done and to catch/process its errors. Let’s imagine that our app is growing and getting new features. Where should we add more separate sequential requests? There can be no question of consistency of our code at all.
However, the Observable Data Services are a good approach and a powerful solution which helps to use built-in features of Angular. You just need to take some points into account:
You should be very good at using RxJS library and Observable Pattern. You should know and distinguish the “cold”, “warm” and “hot” Observable. You have to know how to transform one into another, when to use and which one to use.
The process of catching/handling errors and testing the app is not so easy - it’s pretty complicated to clarify whether it’s behaving according to specs.
Remember that every solution is very custom, that’s why other developers should need time for understanding and maintaining it, especially if we talk about large apps.
As it follows from the above there are some issues within this approach. Trying not to do unnecessary work we were searching for another state management solution and the eye-catching one was REDUX.
Redux Pattern with RxJS

As described in the docs, Redux is "a predictable state container for JavaScript apps”. It offers an easy and very simple solution when data moves in one direction only, it means that data flow is very predictable and explicit.
Here are necessary definitions:
-
Component - view template user can interact with;
-
Action - defines (dispatches) the change in State that is to be made;
-
Reducer - a pure function, meaning, it doesn’t produce side effects , which has access to the current State;
-
Selector - defines which specific data get from the Store;
-
Effect - handles everything that is asynchronous or outside the application.
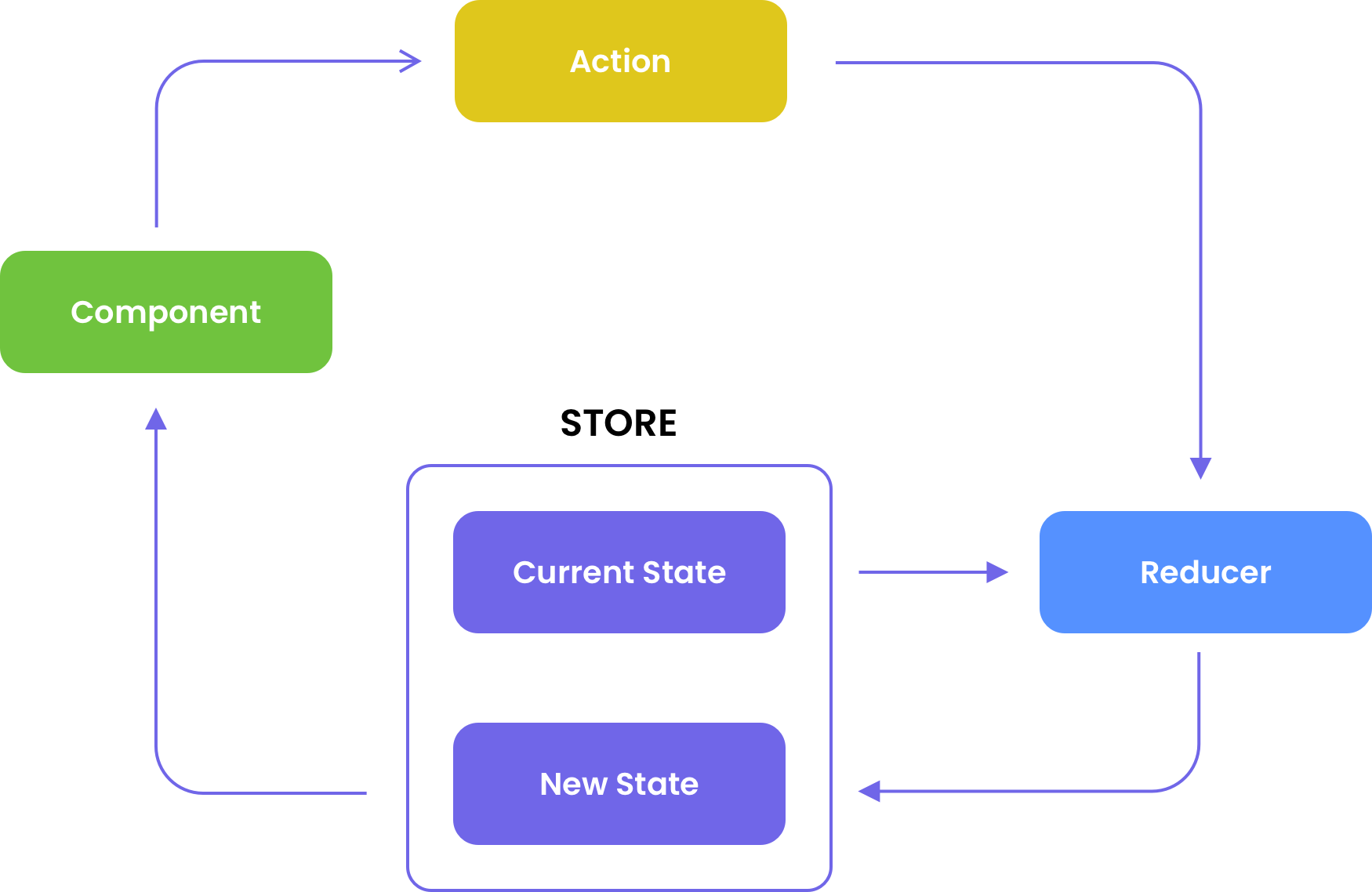
Picture 3
Maybe, it seems difficult and time-taking because you should set up the necessary structure of the app and write much boilerplate code. But let’s find out how it works using this small example that helps to clarify everything and demonstrates the benefits of this approach.
When the user clicks the button in a component’s view template, the corresponding Action is dispatched to the Store. When the action is initiated the Reducer gets the current State and the data from the Action and then it brings back the new State from it. Reducers don’t store or mutate State - they just take the previous State and the Action and give back the new State.
Let’s consider the advantages of Redux:
When you maintain all States in a Store and use the async pipe to wire up to the view you are able to control the change detection that greatly improves the performance in enterprise apps.
Additionally, Redux provides us with Selectors called with the Store’s select method (Picture 4)
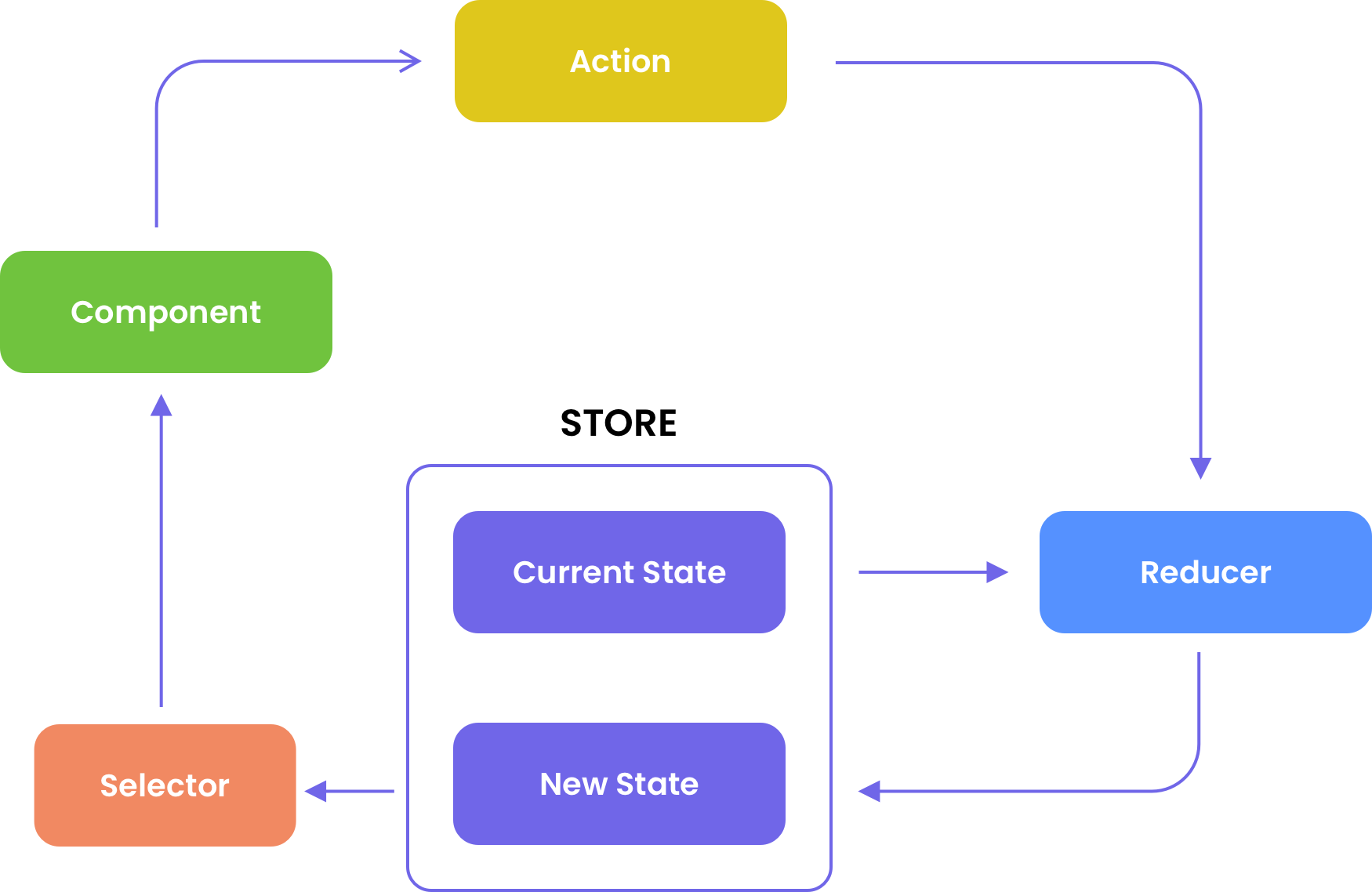
Picture 4
This Store’s select method helps to get the current State with a help of Selector that returns a stream. The last one brings back values whenever State changes. This helps the component to be informed and receive the last data version from the Store.
As you can see from the above-mentioned scheme, the data flow isn’t complicated at all and it’s very transparent. The reason is that the data always comes from one source.
-
Let’s talk about one more advantage. We have already mentioned above that there is such an issue in the Observable Data Services approach as different separate states’ combining. But the selectors easily solve this issue. They can pass and сluster together various slices of the State for creating data which the definite component needs.
-
The third advantage is solving the problem of sequential requests. Look at the chaining and its description: The Effect listens to an Action and executes one or some Actions. And these are listened by some other Effect(s) that runs some new Action(s), being over and over processed by the reducers.
This cycle can have any length and it’s shown in Picture 5.
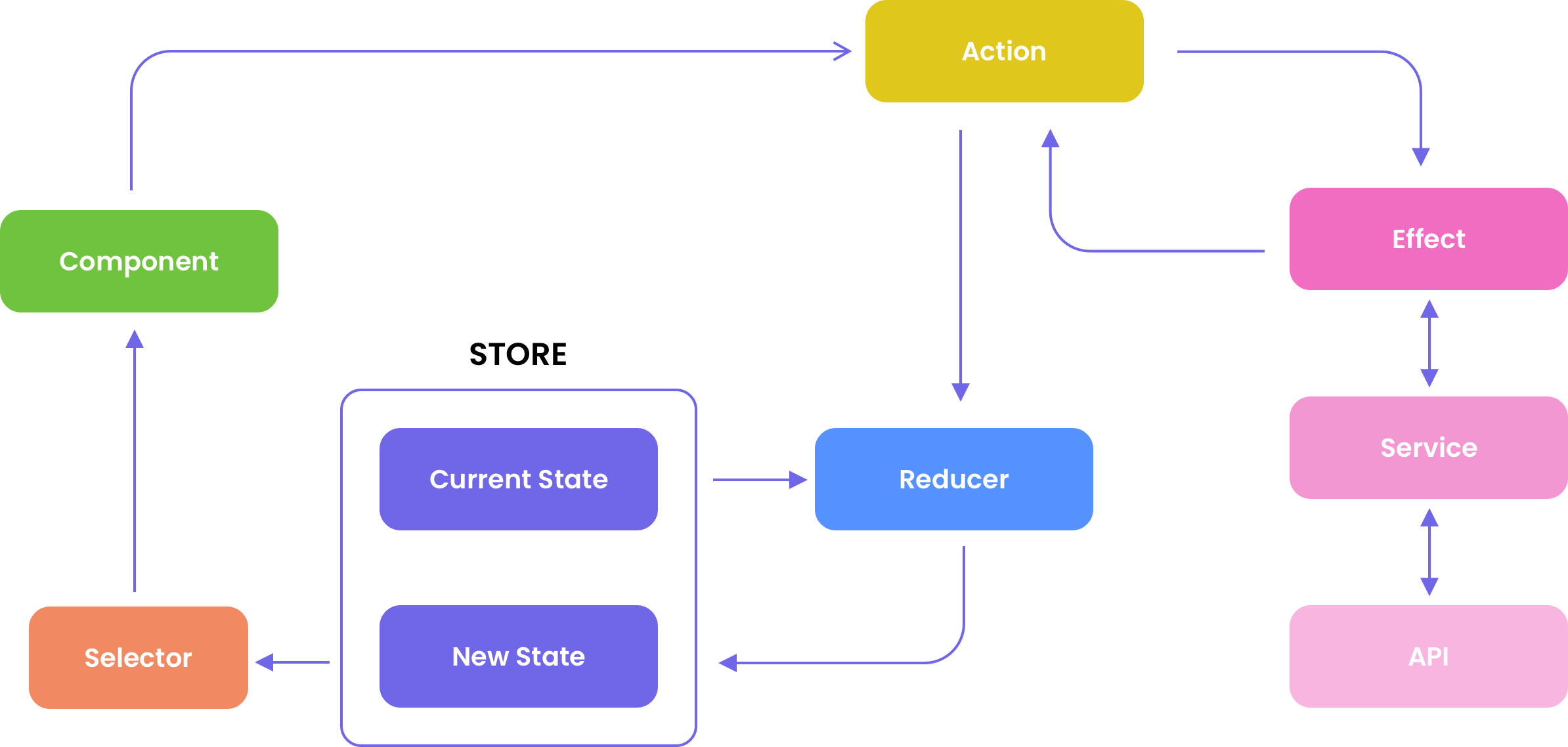
Picture 5
-
Along with the fact that the system is well-defined, we should mention the fourth advantage of the Redux approach: business logic and rendering are distinct. The developers can test these sections independently from one another.
Testing our logic translates into testing of Actions, Selectors and, of course, Reducers, which are pure functions itself and allows us to test complex UIs by asserting that functions return specific data.
Besides, you can get a great npm or browser extension for debugging process - Redux DevTools, and it can save you a lot of time. It’s possible to examine your whole workflow because each State and Action payload can be observed. In case the error message is sent back from the Reducer you can easily find out at which Action this error appeared.
In general, the Redux approach has got many advantages if compared with the custom state management approach. Of course, you will need some time for learning this methodology but as a result, it’s definitely worth it.
Conclusion
In this article, we shared our experience of managing the application State within several approaches. Literally, each one has its own advantages and disadvantages. You should decide which one is meeting your demands, take into account the use case, your organization's needs and restrictions.
As for us, the Redux methodology could be one of the best options because of its functionality and one-way data flow. The app processes become more predictable. Other pros are scalability, reusability, and additionally, it’s easy to understand how the data is shared among all the components and where it is usually stored.
Well, you should opt for Redux only if you determine your project needs a state management tool. Otherwise, you can opt for other choices which were considered with their main pros and cons in this article.
Info for this article was taken from our blog on Medium.




